Thinking in Git
I had the great pleasure of presenting at SEVDNUG with my son this evening. He was a wonderful asset, and a great star. When we were all done, I think his was the bigger applause. I look forward to presenting with him again.
Our topic was Git, the new hotness for version control.
The Abstract of the talk is:
Have you ever looked at Git because it was trendy, but stumbled away dazed? Git isn’t your father’s source control system, but most of your knowledge of TFS, SVN, or other source control systems transfer over just fine. We’ll take your existing knowledge of your Commit / Update VCS and we’ll layer in the methodologies, tools, and communities that Git uses. What’s the difference between pull and update? Isn’t branching and merging dangerous? Can I get colored icons in Windows or Visual Studio? How do I contribute to a GitHub project? We’ll graph Git’s actions in blocks and compare it to git command results. You’ll come away thinking in Git, ready to easily leverage the additional power.
Quite humbly, I think we rocked the house.
What is Git? Git’s website has a pretty good (if a bit verbose) description of Git:
“Git is a free & open source, distributed version control system designed to handle everything from small to very large projects with speed and efficiency. Every Git clone is a full-fledged repository with complete history and full revision tracking capabilities, not dependent on network access or a central server. Branching and merging are fast and easy to do.”
Git’s Methodology Git really has two main tricks, and the focus of all our discussion is to explore in depth these things:
Git has 4 repository locations: the working directory, the staging area, the local repository, and remote repositories. Once you can visualize where your data is, Git is easy.
Git’s magic is just moving labels between nodes. We may call them branches, tags, HEAD, etc, but it’s just an identifier for a node to Git. If you understand how your labels move as you commit, everything else is gravy.
History of Git Git was created by Linus Torvalds in 2005. He’s famous for a few other projects … like Linux. I heard it said once that Linus would take over the world – perhaps not with Linux, perhaps instead with Git.
Where is Git used? Git is used by most major source control hosting firms, and has become a staple at most social coding avenues:
GitHub is the quintessential Git hang-out. It offers both open-source and private repositories (cost is quite reasonable), and really focuses on the social end of coding. (It’s hard to describe the atmosphere and wonderment that is GitHub. You really need to try it to see it.)
BitBucket is the mecca for Mecurial open-source projects, and now provides Git hosting.
CodePlex is the open-source hangout for Microsofties, and includes hosting for TFS, SVN, and most recently, Git.
SourceForge is the old hub of open-source, originally for CVS, now known for SVN, and more recently, they’ve added support for Mercurial and Git.
Want more evidence that Git is ubiquitous? Go to Microsoft’s uber-mecca for open-source – to their project for MVC, Web API, and Razor at http://aspnetwebstack.codeplex.com/. Now click on Source Code, and click Connection Instructions. Ya know what you see? A Git url. No “or SVN”. No “or TFS”. Nope. All you get is Git.
Clearly Git is winning in the realm of version control systems.
Elements of Source Control Systems There are 4 main elements to a source control system:
GUI Tools
Command-line Tools
Node Graph / Commit Log
Storage Map
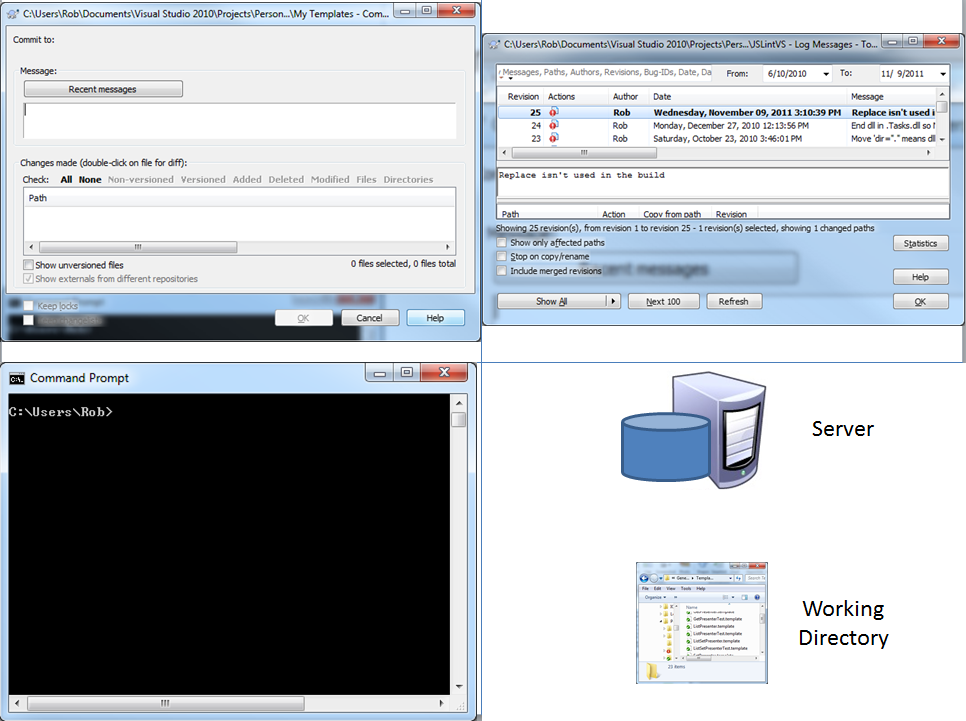
Looking at these 4 elements in an SVN realm, we get something like the following:
TortoiseSVN provides an excellent front-end for the pointy-clicky people.
svn command line is great for power users and for automating and scripting things.
svn log from either the command-line or TortoiseSVN, and you’ve got a great view of SVN’s history.
SVN has really two spots where code lives: the SVN Server, and your Working Directory.
Here’s a graph of the 4 spots in SVN:
Using those same quadrants, we can enumerate the toolset for Git in Windows:
Git Extensions works great as a Git GUI. TortoiseGit does ok, but it forces us to look at Git as if it was a SVN repository. The two can install seamlessly on the same box, playing nicely together.
msysGit is the Git engine and command-line tools, though posh-git is an interesting PowerShell plugin. Most every other tool either depends on or installs msysGit.
kdiff3 comes with Git Extensions, and is a great way to browse git’s commit history and node graph.
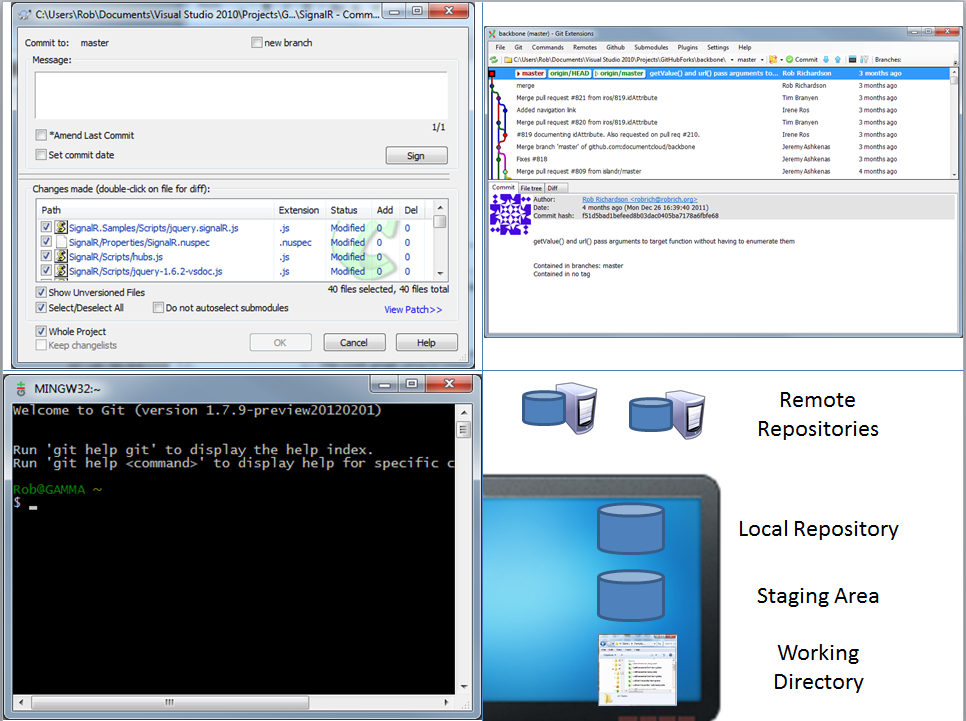
Git’s storage system includes four main sections:
- The working directory – the check-out folder in Windows
- The staging area – the code you’re getting ready to commit
- Your local repository – this is where the majority of the meat is
- Remote repositories – places where you share the code – you need not have these, or you could have lots of connections to remote repositories
The graph we used for git’s parts looks like this:
Now let’s spend a bit more time with the 4 storage areas in Git:
Working directory we know from SVN, TFS, CVS, and other acronymed alphabets.
We’re familiar with “the server”, but in this case “the server” is on our local machine – the “local repository”. That’s kinda weird, but kinda cool. Now I can commit when I’m at a good stopping point, even if I’m not completely done with the task. Ever get “code complete but untested” but want to save your progress but not break the build? That’s the local repository.
The staging area is also a little weird. Why would I have a place between my working, checked-out files and my repository? Well, it allows you to commit parts of things without needing to commit the other parts of things. In time, and with great skill and training, this allows you to commit part of the file if the other parts of it don’t need to be committed yet. It’s a great place to build smaller, more purposeful commits. Alternatively, you may find you don’t need this, and you’ll use the “just get it in already” or “-a” flag to the commit command.
Remote repositories are the most curious. We’ve got a distributed version control system where everyone has a copy of every commit. I can push my changes to you when I’m ready – as a big clump. Or maybe I’ll push them to the CI server. Or maybe I’ll push them to a colleague for code review before I commit to “the build”. Or maybe on a small project, I just keep my source tree alone on my machine and have no remotes.
Everything but the “Remote Repositories” is on my local machine. I can do everything needed with these while on a plane – without network access.
We now have the 4 parts of a source control system in Git. It’s not scary once you know how it works.
Git Commands We did a great job of showing the git commands and mapping their results in a node graph made of felt and string. It was truly a performance, and to do justice, I’d need video. We didn’t tape our presentation, but
http://blip.tv/open-source-developers-conference/git-for-ages-4-and-up-4460524 is a similar video, and the one I used for the majority of the inspiration of this section of the demo. Me and my son took a bit different route, but this video does very well. “A non-cyclical graph node isn’t scary when it looks like this.“ He’s holding up a tinker toy, I’m holding up felt and string. The audience laughs, settles into their comfortable seats, and we’re off to the races.
Here’s a summary of the Git commands and the learning we can get from each one. Go download msysGit, install it, then open up a command prompt or Git shell and follow along. If I’m commenting on one, I’ll add “// <–” to highlight something. Don’t include these as you’re typing the commands.
Start it off:
git init // <– get the repository started; we typically copy an existing repository, but this is simpler for now
Adding files:
Go create a file, add content to it, and substitute your file’s name for <filename>, and leave off the < and >.
git add <filename> // <–It stored the file in the repository right here
git status // <– it shows we’re on the “master” branch (trunk in SVN speak), and that the file is in staging
git commit -m "some message" // <– it added the label “HEAD” to it here, “HEAD” means “working directory is here”
git log // <– each commit has a sha1 hash that uniquely identifies it
The sha1 of each commit is a hash of:
The content of the objects
The hashes of the parent node(s)
Add another file or two, and git log starts looking pretty tasty … and pretty verbose.
git log –oneline –graph –decorate // <– this shows the graph node lines, the first 1⁄2 dozen characters of the hash, and branch labels – very, very handy. After about the third or fourth time typing this, you too will make a shell alias or a batch file to do it easier.
The .git directory:
So now that we have some nice content in the local repository, let’s go pillaging through the .git folder. This .git folder is the actual repository data. There are quite a few tasty nuggets in here, and understanding how they work is very helpful. Open a few in your favorite text editor. But DON’T SAVE THEM! Don’t brick your git! :D
– open the HEAD file – it’s the sha1 of the commit that the HEAD label points to.
– open a few files in the refs folder – they’re also text files that contain the sha1 of the position of the label that is their name.
– look through the objects folder, and note that the first 2 digits of the sha1 is the folder, the rest of the sha1 is the file – this is where the actual content is stored, zlib compressed. Open this in a text editor, and you’ll get some pretty zany zaph dingbats.
Branching:
In Git, by convention, most things are done in branches. Branches are very, very cheap in git, they’re just labels. Let’s experiment with branching and merging, and see why they aren’t nearly the pain you’ve experienced wit non-distributed version control systems.
git branch somebranch // <– This creates the branch but doesn’t switch to it
git checkout somebranch // <– This switches to it
git status // <– check that you’re on the branch you thought you were on
now create a file, add it, and commit it
git log –oneline –graph –decorate // <– note that somebranch and HEAD moved, master didn’t
It’s worth re-emphasizing that git’s branches are just labels on nodes. We didn’t copy all the files when we branched, the repo is no bigger for having the branch. It’s merely another name for the node besides it’s sha1 hash name.
Merging (fast-forward):
Merging is also no big deal in git.
git checkout master // <– get back to master
git merge somebranch // <– merge somebranch into master
git commit -m "merged somebranch" // <– commit this change
git log –oneline –graph –decorate // <– note that master now moved to match somebranch and HEAD
We just moved the label – very simple. The paths didn’t diverge, so we needed only push the master label forward. Gorgeous.
Delete the Branch:
In git, a branch is just a label. If we don’t need to refer to the commits by label anymore, we can remove the label. It doesn’t delete code, and we can always get back to the node by it’s sha1 hash. It merely removes the label from the node.
git branch -d somebranch
git log –oneline –graph –decorate
Branch / Merge (not fast-forward):
git checkout -b branch1 // <– checkout -b creates the branch and switches to it in one shot
create a new file, add it, commit it
git checkout master // <– get back to before this new file was added
git checkout -b branch2 // <– simulate a second developer
create another new file, add it, commit it
We now have an interesting scenario: we have two “ends of the trail” – two “tips”. So let’s merge them together.
git checkout master // <– get back to home base
git merge branch1 // <– merge in the first branch
git commit -m "merge branch1"
git merge branch2
git commit -m "merge branch2"
git log –oneline –graph –decorate
See the nice diamond shape? Pretty! Try that with your silly little linear-only SVN.
Also notice where your tags are. HEAD and master are at the top of the graph, but branch1 and branch2 are still where they were. We could merge this new master into them (fast-forward), but we probably don’t need to. More than likely, once this feature is done and integrated and enough time has passed, we can just delete these branch labels.
Working with Remote Repositories:
Now that we’ve got the hang of adding, committing, branching, and merging, and watched how it affects labels in our local repository, let’s take a wander through how we can share this code with others.
Create a new folder outside the previous folder. Rather than git init in this new folder, let’s “initialize” this repository by linking to the previous repository.
git clone ../path/to/other/repo
The “path” can be a windows file path, it can be an http url, it could be git://github.com/username/repo.git. It doesn’t matter where it came from, when we’re done here, we have an exact duplicate of the other repository. Prove this to yourself by running git log:
git log –oneline –graph –decorate
You’ve got all the history, all the tags, but something is interesting. You’ve not only got your own HEAD and master labels, you’ve got some new labels: origin/master and origin/HEAD (and any other branches). These new labels show you where the remote connection is.
git remote // <– this one lists the remote links you’ve configured
git remote -v // <– this one gives you the path to the other repository
Now from here, we need to talk a little logistics. In TFS or SVN land, we did update and commit. Those two commands are the commands we use in Git when talking about transitioning from and to our working directory and local repository. So what do we call it when we’re moving between our local repository and a remote repository? Pull and push.
git pull origin master // <– get latest from them to my local repository
git push origin master // <– send my latest changes to them
If there’s no major changes when I pull, I just commit to fast-forward my tags to the end of the line, and we’re good to go. If there were changes on both sides, I may need to resolve a conflict before merging. Git gives me the standard “theirs”, “mine”, “fix it” – both as diffs in command-line or as pretty diff compare views in GUI tools. When I’m done, I commit, and it’s now combined together.
By convention, we’ll probably want to designate one copy of the repository as “the master copy”, and all push and pull to that one (unless unusual circumstances allow us to push and pull intermediary content between members of our team). Though git technically doesn’t need a “server to rule them all”, it’s always nice to have a central place where we can back up the corporate assets and where the CI / Build process can look to for “the latest and greatest”.
Advanced Topics It wouldn’t be fair to leave you in the dark about these advanced keywords that come in very handy. Alas, it also wouldn’t be fair for me to confuse you with these details while you’re first learning git. These tools are immensely handy though, and when you’ve got time, Google each of these terms:
git reset
git rebase
git cherry pick
git stash
git flow
Bringing it Together We’re now concluding where we began: Git has really two major things that differentiate it from the SVN / TFS methodology we’re used to:
Git has 4 repository locations: the working directory, the staging area, the local repository, and zero or more remote repositories. We saw how we could work with the staging area (
git add; git status), and in time we’ll see how this view of the commit-in-embryo can be a great tool for forming cohesive, descriptive commits.Git’s magic is just moving labels between nodes. We saw throughout the command demos that as we made changes, we just created nodes and moved / added / removed labels from them. These “branches” weren’t expensive, they were just organizational tools. If a “branch” node path doesn’t work out, just abandon it, go back to master, and try again. It’s not a lock-step linear process where everyone inherits my mistakes. It’s just a system of nodes.
Git can now be a very, very powerful tool. Given the popularity and pervasiveness of git, I foresee it’s just a matter of time before git is the new svn, and svn becomes the next cvs … or worse, the next SourceSafe. And if you learn nothing else from this presentation of “Thinking in Git”, learn this: friends don’t let friends use SourceSafe. :D
Great Git Resources
http://blip.tv/open-source-developers-conference/git-for-ages-4-and-up-4460524